
Now more than ever, the data we all generate is becoming increasingly important. With the increase in usage of generative AI tooling, everyone from regular people to corporations is realizing the importance of their data. This realization also wasn't lost on nefarious actors. In 2025, many of the most important data breaches weren't simply a matter of providing third parties and employees with too much access but instead, a matter of data architecture. For example, Blue Shield of California disclosed that member data had been shared from its websites to Google advertising systems through analytics tooling, affecting 4.7 million people. How can organizations, businesses, and developers build better products for their users while still providing strong data privacy guarantees?
Enter Multiparty Computation (MPC)
So what actually is MPC?
At the heart of many of these breaches is the underlying assumption of modern software; in order to run any functionality, one needs to gather sensitive information into one place in order to gain insight from it. MPC turns that assumption on its head; MPC is a subfield of cryptography aimed at designing techniques (e.g., data analysis, cryptographic signing) for turning common functionality into distributed functions in which none of the parties know the inputs into that function while still gaining the same output.
Like many innovative computer science techniques, the foundations of MPC can be traced back to the early 80’s. The most famous example that conceptually illustrates MPC was Andrew Yao’s Millionaires' Problem in 1982, which showcases two theoretical millionaires who want to know who is richer without either of them disclosing their actual net worth.
What makes MPC different from the more commonly deployed cryptographic primitives is that it isn't a singular algorithm itself, but instead more of a transformation process via from a centralized process over centralized data turns into a distributed network over decentralized data while keeping the same core functionality!
Why Now?
Throughout the years, the conversation around privacy has shifted. GDPR, CCPA, and a wave of numerous high-profile data incidents have made users more aware and regulators more proactive. Many regulated industries (e.g., Fintech, Health) have begun to question whether centralized data ownership is on the right path or not.
At the same time, MPC has long had a reputation for being too theoretical, and the gap between theory and production has been too wide for many engineering teams to bridge. Writing sound MPC protocols from scratch required deep cryptographic expertise, and their performance overheads were too restrictive for many use cases.
That has since changed. A combination of algorithmic improvements, purpose-built runtimes, and developer-facing tooling has turned MPC into viable, deployable infrastructure.
However, that combination is only part of the bigger picture. Privacy has long meant placing blind faith in a company’s privacy policy. Most companies mean it when they say “trust us” – they’re not trying to misuse your data. We believe that users shouldn’t have to hand over their data in exchange for a useful product. You should be able to build something genuinely valuable without holding data you were never meant to hold in the first place.
But what does MPC actually look like in practice?
MPC in the Real World
The first large-scale, real-world application of MPC wasn’t a bank or a tech company, but a sugar beet auction in Denmark in January 2008. Around 1,200 Danish sugar beet farmers needed to trade production contracts, but couldn't agree on a neutral auctioneer. MPC solved the issue by running the auction without anybody seeing each other’s bids, computing the market-clearing price across three distributed servers in about 30 minutes.
While that auction happened over twenty years ago, MPC has been applied across a variety of industries for various use cases:
Coinbase uses key splitting for cryptocurrency wallet transactions.
Coinbase also relies on threshold signatures for secure signatures of private keys within cryptocurrency.
Inventory matching is used by J.P Morgan, where clients match their orders with reduced market impact all while maintaining privacy
In these cases, nobody had to hand over their data, and nobody had to ask their users to choose between their privacy and a useful product.
However, how does MPC actually work?
How It Actually Works
Let’s walk through how MPC can be applied to an existing use case.
First, let’s briefly introduce a common algorithm known as Shamir’s secret sharing. Fundamentally, secret sharing is a method for splitting a secret among a group of people. Imagine you have a secret message in the form of a puzzle. You distribute the pieces of the puzzle to each person in your group in advance. Later, when the group needs to read your message, members of the group coordinate to meet in person. At that point, they construct the puzzle with their pieces to read the message you sent them. In Shamir's secret sharing, the reconstruction process is known as Lagrange interpolation. Both of them form the basis of many MPC protocols.
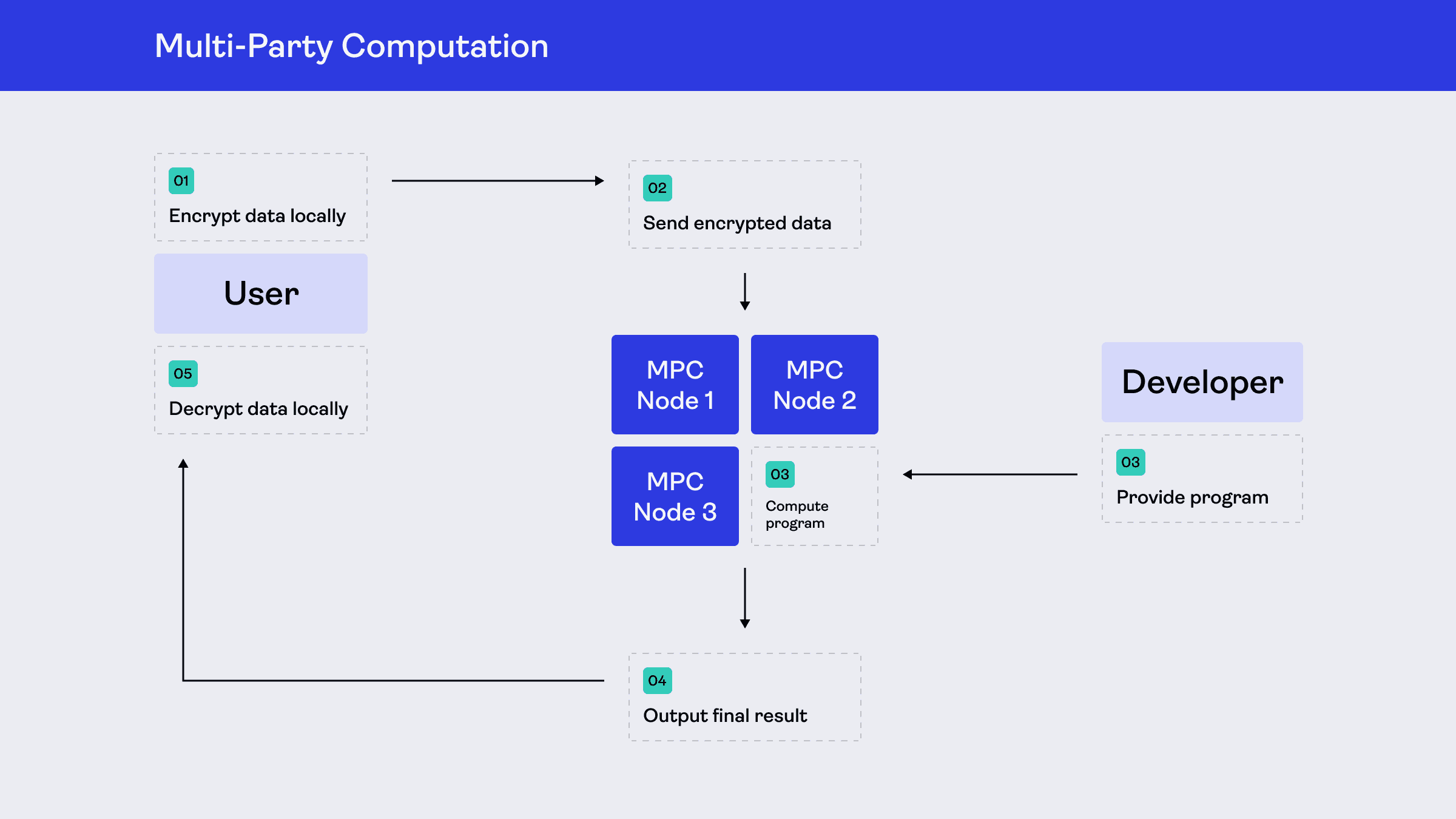
Going back to the aforementioned Blue Shield data breach, at its core, Blue Shield was sending measurement data to Google Analytics (GA) to gain insights about how its users navigate its websites. From the perspective of a Blue Shield user, the typical flow would be:
Visit blueshield.com
A GA cookie gets stored in the browser
Every event gets recorded and sent to GA
GA stores the event logs, aggregates the events, and calculates statistics about them
GA displays the insights in a dashboard for a trusted employee at Blue Shield to read
Steps 3 to 5 are where MPC comes in. With MPC, that same flow becomes:
Visit blueshield.com
Instead of each event being sent to GA, a particular measure from a set of events, such as a mean, is split into secret shares and sent to a network of non-colluding nodes
These nodes calculate statistics over the secret shared measurements
The nodes send the aggregate statistics to a dashboard for further analysis
The data flow changes from browser → GA stores event logs → GA calculates dashboard to browser → MPC network computes over secret shared measurements → Blue Shield only gets aggregated statistics.
With MPC, as a developer, you stop designing around user data and start designing around the computations that actually matter. The questions around compliance and breaches change. But what you owe your users never does.
Where do I go from here?
The gap between MPC theory and what you can actually ship is closing faster than most people realize — enabling private by design architectures without having to change what your product can do.
As we've all seen over the years, cybercriminals are increasingly targeting valuable user data, making everyone's infrastructure a breach magnet. That's why everyone needs to start rethinking how to build products with privacy in mind from the start. It is no longer enough to encrypt user data only at rest and in transit. Data needs to be encrypted throughout the entire product lifecycle.
At Stoffel Labs, we are bridging the gap between MPC theory and deployment via the Stoffel Stack while building the privacy-first products that enable you to grow while keeping your users safe.
